

CAG e RAG: Explorando o Potencial e as Limitações de cada técnica
- 23 de mar. de 2025
- 11 min de leitura
Atualizado: 5 de jun.
O avanço dos modelos de linguagem com janelas de contexto cada vez maiores está mudando a forma como empresas pensam sobre recuperação de conhecimento, geração de respostas e arquitetura de agentes de IA. Durante os últimos anos, o Retrieval-Augmented Generation, conhecido como RAG, tornou-se uma das abordagens mais usadas para conectar LLMs a bases externas de conhecimento. A lógica é simples: quando o usuário faz uma pergunta, o sistema busca documentos relevantes, envia esses trechos ao modelo e gera uma resposta contextualizada.
O Cache-Augmented Generation, ou CAG, surge como uma alternativa para cenários específicos. Em vez de recuperar documentos a cada consulta, o CAG pré-carrega uma base de conhecimento controlada na janela de contexto do modelo e reaproveita um cache de execução, normalmente associado ao KV-cache do modelo. A proposta foi apresentada no artigo Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks, que descreve o CAG como uma abordagem capaz de eliminar a etapa de recuperação em tempo real quando a base de conhecimento é limitada, estável e cabe dentro da janela de contexto do LLM.
A pergunta principal, porém, não é se o CAG “mata” o RAG. A questão mais importante é: em quais cenários o CAG realmente faz sentido, onde ele falha e como as duas abordagens podem coexistir em arquiteturas corporativas de IA?
O que é RAG?
RAG é uma arquitetura que combina a capacidade generativa de um modelo de linguagem com uma fonte externa de conhecimento. O modelo não depende apenas do que aprendeu durante o treinamento; ele também recebe documentos, trechos ou dados recuperados em tempo de execução. O paper original de RAG descreve essa lógica como a combinação entre memória paramétrica, presente no modelo, e memória não paramétrica, representada por um índice externo de documentos.
Na prática, um pipeline RAG costuma seguir este fluxo:
O usuário faz uma pergunta.
O sistema transforma a pergunta em uma consulta.
Um mecanismo de busca, vetorial ou híbrido, recupera trechos relevantes.
Os documentos recuperados são adicionados ao prompt.
O LLM gera a resposta com base nesse contexto.
O sistema pode exibir fontes, evidências e trechos usados.
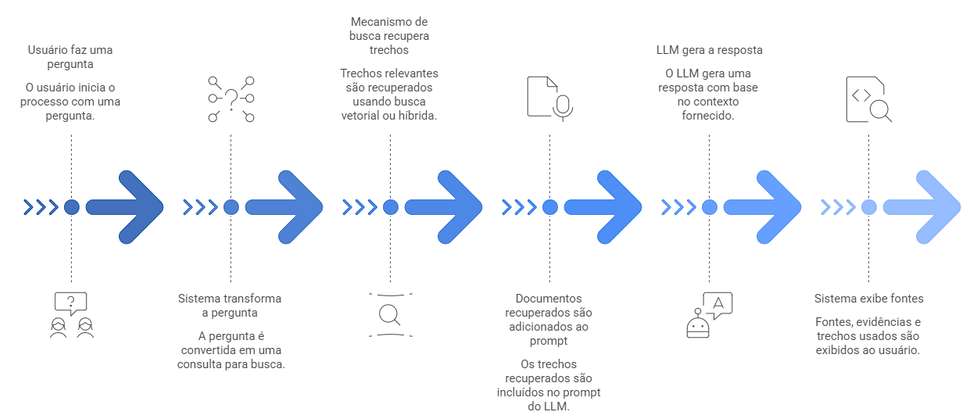
Essa abordagem é poderosa porque permite conectar o modelo a documentos atualizados, bases extensas e informações que mudam com frequência. Ela é útil para bases jurídicas, documentação técnica, atendimento corporativo, políticas internas, manuais, catálogos de produto, análise de contratos e agentes corporativos integrados a dados empresariais.
O problema é que o RAG também adiciona complexidade. A qualidade da resposta depende da qualidade do chunking, dos embeddings, do ranking, da busca, dos filtros de permissão, da atualização do índice e da forma como os trechos são enviados ao modelo. Uma falha em qualquer parte desse pipeline pode fazer o LLM responder com contexto incompleto, irrelevante ou mal interpretado.
O que é CAG?
CAG é uma abordagem que tenta remover a etapa de recuperação em tempo real. Em vez de buscar documentos a cada consulta, o sistema carrega previamente os documentos relevantes dentro da janela de contexto estendida do modelo. Depois, o estado de inferência desse contexto é armazenado em cache para ser reutilizado nas próximas perguntas.
Em termos simples: no RAG, o sistema procura o conhecimento na hora da pergunta. No CAG, o conhecimento já está carregado antes da pergunta acontecer.
Essa diferença parece pequena, mas muda bastante a arquitetura. O CAG reduz a dependência de mecanismos de busca, diminui a latência causada pela recuperação e evita erros de seleção de documentos. O paper sobre CAG descreve três fases principais: pré-carregamento do conhecimento externo, inferência com o cache pré-computado e reset do cache para manter o desempenho entre sessões.
É importante deixar claro: CAG não significa treinar novamente o modelo. Também não significa salvar respostas prontas. O cache usado nesse contexto está ligado ao estado computacional gerado quando o modelo processa previamente os documentos. Assim, quando a pergunta chega, o modelo já parte de um contexto carregado, sem precisar reconstruir tudo a cada consulta.
Como funciona o CAG na prática?
O fluxo do CAG pode ser dividido em duas grandes fases: inicialização e inferência.
Fase 1: Inicialização

A primeira etapa é a preparação da base de conhecimento. Os documentos precisam ser coletados, limpos, organizados, versionados e convertidos para um formato adequado ao modelo. Essa etapa exige cuidado porque tudo o que for carregado no contexto pode influenciar a resposta.
Depois disso, os documentos são enviados ao LLM dentro da janela de contexto. O modelo processa esse conteúdo e gera um estado interno reutilizável, frequentemente descrito como KV-cache. Esse cache pode ser mantido em memória ou armazenado para uso posterior, dependendo da implementação.
Essa etapa concentra o custo inicial do CAG. O sistema paga o custo de processar o conhecimento antes das consultas, em vez de pagar uma parte desse custo a cada pergunta.
Fase 2: Inferência

Quando o usuário faz uma pergunta, o sistema não precisa buscar documentos em um índice vetorial. A consulta é combinada com o contexto já carregado, e o modelo gera a resposta com base nesse conhecimento pré-processado.
O resultado esperado é uma resposta mais rápida, com menos dependência de componentes externos. O CAG também reduz o risco de o sistema recuperar o documento errado, deixar de recuperar uma informação essencial ou rankear mal os trechos mais importantes.
Fase 3: Reset e atualização do cache

Depois de uma interação, o cache pode crescer com novos tokens gerados durante a conversa. Para manter o desempenho, o sistema precisa resetar ou truncar partes adicionadas durante a inferência, preservando o conhecimento base. O paper do CAG descreve esse processo como uma forma de manter velocidade e responsividade sem recarregar tudo a partir do zero.
Como ler o fluxograma do CAG

O fluxograma do CAG deve mostrar uma separação clara entre a fase de inicialização e a fase de inferência.
Na fase de inicialização, os documentos da base de conhecimento passam por processamento, limpeza e organização. Em seguida, são carregados na janela de contexto estendida do LLM. O sistema cria ou reaproveita o cache relacionado a esse contexto.
Na fase de inferência, o usuário envia uma consulta. O sistema processa a pergunta e a encaminha ao modelo, que já possui o conhecimento necessário carregado. A resposta é gerada sem uma etapa de busca em tempo real.
A conexão entre as duas fases é o ponto central do CAG: o contexto preparado antes da consulta passa a sustentar várias inferências posteriores. Por isso, o desenho deve deixar claro que o CAG não elimina a preparação do conhecimento. Ele desloca essa preparação para antes da interação com o usuário.
Vantagens do CAG
1. Menor latência durante a consulta
A principal vantagem do CAG é reduzir a latência da etapa de inferência. Como o sistema não precisa executar busca, ranking e montagem de contexto a cada pergunta, a resposta pode ser mais rápida. Nos experimentos apresentados no paper, a abordagem com CAG reduziu significativamente o tempo de geração em comparação com cenários em que o contexto precisava ser processado dinamicamente durante a inferência.
2. Menos erros de recuperação
Em pipelines RAG, uma resposta ruim muitas vezes nasce antes do modelo gerar qualquer texto. O retriever pode selecionar o documento errado, ignorar um trecho relevante ou entregar contexto insuficiente. O CAG reduz esse tipo de falha porque o modelo recebe previamente todo o conjunto de conhecimento considerado relevante para aquele domínio.
Essa vantagem é especialmente importante em bases pequenas e fechadas, como manuais técnicos, políticas internas, documentação de produto, FAQs corporativos e playbooks operacionais.
3. Arquitetura mais simples
Um sistema RAG maduro costuma envolver indexação, embeddings, banco vetorial, ranking, chunking, filtros, reprocessamento de documentos e monitoramento de recuperação. O CAG pode simplificar parte dessa arquitetura quando a base de conhecimento é pequena o suficiente para caber no contexto do modelo.
Menos componentes podem significar menos pontos de falha, menor esforço de manutenção e maior previsibilidade operacional.
4. Consistência de contexto
Como todos os documentos relevantes são carregados juntos, o modelo pode responder considerando uma visão mais ampla da base. Em alguns casos, isso ajuda em perguntas que dependem de relações entre seções diferentes de um mesmo conjunto de documentos.
Essa característica é útil quando a base é coerente, bem estruturada e não possui conflitos internos. Caso existam documentos contraditórios, políticas desatualizadas ou versões divergentes, o CAG pode amplificar a confusão. A curadoria da base continua sendo indispensável.
Limitações do CAG
1. A janela de contexto ainda é um limite real
Modelos com janelas longas criam novas possibilidades, mas isso não significa que qualquer base corporativa possa ser carregada integralmente. Documentos extensos, bases com milhares de arquivos, repositórios técnicos, históricos de atendimento e dados transacionais podem ultrapassar rapidamente o limite prático do contexto.
Mesmo quando o conteúdo cabe na janela, ainda existe o desafio de garantir que o modelo use as informações corretas. Contexto longo não é sinônimo automático de raciocínio perfeito.
2. Atualização de conhecimento pode ficar mais difícil
RAG lida melhor com bases dinâmicas. Quando um documento muda, o sistema pode atualizar o índice, reprocessar os embeddings e recuperar a nova versão na próxima consulta.
No CAG, a atualização exige reconstruir ou atualizar o cache. Isso pode ser simples em bases pequenas, mas se torna mais sensível em ambientes com alterações frequentes. Políticas internas, preços, status de pedidos, registros financeiros, eventos operacionais e dados de clientes podem mudar rápido demais para um modelo baseado em contexto pré-carregado.
3. Custo inicial e consumo de memória
O CAG desloca custo para a fase de inicialização. Processar uma base inteira e manter o cache disponível pode exigir memória, infraestrutura e orquestração. Esse custo pode compensar quando muitas consultas usam a mesma base estática. Pode não compensar quando a base muda com frequência ou quando cada usuário precisa de um contexto muito diferente.
4. Governança e segurança ficam críticas
Carregar documentos inteiros no contexto do modelo exige controle rigoroso. Em empresas, nem todo usuário pode acessar todos os documentos. Um cache compartilhado sem segregação adequada pode criar risco de vazamento de informações.
Por isso, CAG precisa ser desenhado com políticas claras de acesso, versionamento, expiração de cache, trilhas de auditoria e segregação por perfil, cliente, domínio ou unidade de negócio.
Em ambientes regulados, essa camada de governança pode ser mais importante que a própria escolha entre CAG e RAG.
5. Menor flexibilidade para perguntas abertas
CAG funciona melhor quando o universo de conhecimento é delimitado. Perguntas abertas, bases muito grandes, consultas que exigem dados recentes ou buscas em múltiplos sistemas favorecem o RAG ou uma arquitetura híbrida.
CAG substitui RAG?
Não de forma geral.
CAG é uma alternativa relevante para cenários específicos, principalmente quando a base de conhecimento é finita, estável, bem organizada e cabe dentro da janela de contexto do modelo. RAG continua mais adequado para bases grandes, dinâmicas, distribuídas e com necessidade de rastrear fontes em tempo real.
A melhor decisão não deve partir da popularidade da técnica, mas da natureza do problema. Uma empresa precisa avaliar o tamanho da base, a frequência de atualização, os requisitos de segurança, o nível de rastreabilidade exigido, a latência tolerável e o custo operacional.
Em muitos casos, a resposta mais madura será híbrida.
RAG e CAG: um caminho híbrido
O próprio paper sobre CAG reconhece a possibilidade de abordagens híbridas, com um contexto base pré-carregado e recuperação seletiva para casos específicos ou consultas que exigem informações adicionais.
Essa combinação pode funcionar assim:
O CAG mantém carregado um núcleo estável de conhecimento: políticas, manuais, documentação base, regras de negócio e instruções operacionais.
O RAG entra quando a consulta exige informação dinâmica, documentos menos frequentes ou dados que não cabem no contexto fixo.
APIs e ferramentas corporativas são acionadas quando a resposta depende de ações, consultas transacionais ou dados em tempo real.
Uma camada de governança controla permissões, logs, métricas, custos, qualidade e rastreabilidade.
Esse modelo é particularmente interessante para agentes de IA corporativos. Um agente pode operar com um contexto fixo de domínio, usar RAG para complementar lacunas e acessar ferramentas corporativas quando precisa executar tarefas. O resultado é uma arquitetura mais equilibrada: velocidade quando o conhecimento é previsível, flexibilidade quando a consulta exige busca, e controle quando a operação envolve sistemas críticos.
Quando usar CAG?
CAG tende a fazer sentido quando:
A base de conhecimento é pequena ou média.
O conteúdo muda pouco.
A mesma base será consultada muitas vezes.
A latência precisa ser baixa.
O domínio é bem definido.
A empresa quer reduzir a complexidade do pipeline de recuperação.
O risco de recuperar documentos errados é maior que o custo de carregar o contexto completo.
Exemplos práticos incluem assistentes para manuais técnicos, documentação de produto, FAQs internas, políticas de RH, playbooks de suporte, guias de onboarding, procedimentos de atendimento e bases regulatórias estáveis.
Quando usar RAG?
RAG continua sendo a melhor escolha quando:
A base é muito grande.
Os documentos mudam com frequência.
É necessário citar fontes com precisão.
O sistema precisa respeitar permissões granulares por usuário.
A consulta pode envolver múltiplos repositórios.
O conteúdo não cabe na janela de contexto.
A empresa precisa recuperar dados atualizados em tempo real.
A auditoria exige saber exatamente quais documentos sustentaram a resposta.
Exemplos incluem portais corporativos com milhares de documentos, bases jurídicas, repositórios técnicos vivos, atendimento com histórico de clientes, sistemas financeiros, documentação regulatória dinâmica e agentes conectados a múltiplos departamentos.
Como decidir entre CAG, RAG ou híbrido
Uma decisão técnica madura pode seguir alguns critérios:
1. Tamanho da baseSe a base cabe com folga na janela de contexto e mantém qualidade de resposta, CAG pode ser considerado. Se a base é grande demais, RAG tende a ser mais viável.
2. Frequência de atualizaçãoConteúdo estático favorece CAG. Conteúdo dinâmico favorece RAG.
3. Requisitos de latênciaCAG pode reduzir o tempo de resposta porque remove a etapa de recuperação. RAG pode exigir otimização adicional de busca, ranking e montagem de prompt.
4. Segurança e permissõesBases com acesso granular exigem cuidado especial. RAG pode aplicar filtros no momento da busca. CAG precisa de caches segmentados e políticas rígidas.
5. Necessidade de explicabilidadeRAG facilita a exposição de fontes recuperadas. CAG pode exigir mecanismos adicionais para apontar evidências dentro do contexto pré-carregado.
6. Custo por consultaCAG pode ser eficiente quando há muitas perguntas sobre a mesma base. RAG pode ser mais econômico quando as perguntas variam muito ou quando não compensa manter grandes caches.
7. Complexidade operacionalCAG reduz componentes de recuperação, mas aumenta a importância do versionamento do contexto e da gestão de cache. RAG adiciona engenharia de busca, mas oferece mais flexibilidade. Neste artigo aqui comparo mais ainda.
Métricas que devem ser monitoradas
Um sistema CAG, RAG ou híbrido precisa ser avaliado com métricas técnicas e de negócio. Algumas das principais são:
Latência p50, p95 e p99.
Custo por resposta.
Taxa de respostas corretas.
Taxa de alucinação.
Cobertura da base de conhecimento.
Tempo de atualização da base.
Consumo de memória.
Taxa de falhas de recuperação, no caso de RAG.
Qualidade das fontes citadas.
Satisfação do usuário.
Taxa de escalonamento para atendimento humano.
Logs de auditoria por consulta.
Conformidade com políticas de acesso.
Sem essas métricas, a discussão entre CAG e RAG vira preferência técnica. Com métricas, a arquitetura passa a ser avaliada pelo impacto real na operação.
O papel da governança em arquiteturas com CAG e RAG
Empresas não precisam apenas de respostas rápidas. Precisam de respostas seguras, auditáveis e alinhadas ao contexto do negócio.
CAG pode parecer mais simples porque remove a busca em tempo real, mas isso não elimina a necessidade de governança. A base pré-carregada precisa ser aprovada, versionada e monitorada. O cache precisa ter expiração, segregação e controle de acesso. As respostas precisam ser avaliadas continuamente.
RAG também exige governança. Índices vetoriais precisam ser atualizados, documentos precisam respeitar permissões e os mecanismos de recuperação precisam ser monitorados. Um pipeline RAG sem controle pode entregar respostas aparentemente precisas com base em trechos incorretos ou desatualizados.
A arquitetura mais segura é aquela que trata IA como sistema de produção, com observabilidade, testes, auditoria, controle de custo e mecanismos de rollback. Essa visão se conecta diretamente ao avanço de práticas como LLMOps, AgentOps, AIOps e DevOps AI em ambientes corporativos.
Como aproveitar CAG e RAG em agentes corporativos
Em agentes de IA para empresas, a escolha entre CAG e RAG deve ser parte de uma arquitetura maior. Um agente raramente depende apenas de texto. Ele precisa entender contexto, consultar dados, seguir regras, respeitar permissões e, em alguns casos, executar ações em sistemas corporativos.
Uma arquitetura robusta pode combinar:
CAG para conhecimento estável e frequentemente acessado.
RAG para documentos amplos, dinâmicos ou pouco previsíveis.
MCP e ferramentas corporativas para acesso controlado a APIs, bancos, sistemas legados e fluxos operacionais.
AgentOps para monitorar comportamento, custo, latência, segurança e qualidade.
Governança para definir escopo, limites de atuação, trilhas de auditoria e aprovação humana em fluxos críticos.
Esse desenho evita uma visão simplista da IA generativa. A pergunta deixa de ser “qual técnica é melhor?” e passa a ser “qual composição arquitetural entrega mais valor, com menor risco e maior controle?”
Conclusão: CAG não elimina RAG, mas amplia o repertório arquitetural
CAG é uma evolução importante na forma de pensar sistemas de conhecimento com LLMs. Ele mostra que nem toda aplicação precisa de um pipeline RAG completo. Para bases estáticas, pequenas e bem governadas, pré-carregar contexto e reutilizar cache pode reduzir latência, simplificar a arquitetura e melhorar a consistência das respostas.
RAG, porém, continua essencial para bases extensas, dinâmicas e distribuídas. Ele oferece flexibilidade, atualização mais simples e melhor suporte para recuperação com fontes explícitas.
O caminho mais promissor para empresas está na combinação inteligente dessas abordagens. CAG pode sustentar o contexto fixo de um domínio. RAG pode complementar consultas mais amplas. Ferramentas corporativas podem conectar agentes a sistemas reais. A governança garante que tudo funcione com segurança, rastreabilidade e escala.
Para operações complexas, a vantagem competitiva não está em adotar a técnica mais recente isoladamente. Está em desenhar uma arquitetura de IA capaz de escolher o mecanismo certo para cada tipo de conhecimento, cada nível de risco e cada necessidade de negócio.


Comentários