

Evaluation Suite para agentes de IA: como testar comportamento antes do deploy
- 24 de jun.
- 19 min de leitura

Entenda como uma Evaluation Suite ajuda empresas a testar comportamento, segurança, qualidade e governança de agentes de IA antes do deploy em produção.
Agentes de IA corporativos não devem ser avaliados apenas pela qualidade de uma resposta isolada. Antes do deploy, é preciso testar comportamento, uso de ferramentas, aderência a políticas, segurança, custo, latência, rastreabilidade e capacidade de operar com dados reais. Uma Evaluation Suite transforma esses critérios em gates de release para colocar agentes em produção com mais controle.
A adoção de agentes de IA nas empresas está avançando rápido. Muitas organizações já passaram da fase de curiosidade e começam a desenhar copilots internos, agentes de workflow, agentes de atendimento, agentes de conhecimento, agentes de infraestrutura e sistemas agênticos integrados a APIs, bancos de dados, documentos, eventos e ferramentas corporativas.

O desafio mudou.
A pergunta já não é apenas “o agente responde bem?”. Em ambientes corporativos, a pergunta mais importante é: “o agente se comporta corretamente quando recebe contexto incompleto, instruções ambíguas, dados sensíveis, ferramentas disponíveis, regras de negócio conflitantes e pressão operacional em tempo real?”.
Essa diferença é crítica.
Um chatbot simples pode errar uma resposta. Um agente corporativo pode chamar uma API, abrir um chamado, consultar dados confidenciais, acionar uma rotina, recomendar uma decisão, publicar um evento no Kafka, interagir com um MCP Server ou influenciar um fluxo de negócio. Quando a IA sai do laboratório e entra na operação, testar apenas outputs individuais deixa de ser suficiente.
É nesse contexto que entra a Evaluation Suite para agentes de IA.
Uma Evaluation Suite é um conjunto estruturado de avaliações contínuas que mede se um agente está pronto para operar com segurança, qualidade, governança e previsibilidade. Ela funciona como uma camada de validação antes do deploy e como um mecanismo de monitoramento depois que o agente entra em produção.
Em outras palavras: a Evaluation Suite transforma agentes de IA em software governável.
O que é uma Evaluation Suite para agentes de IA

Uma Evaluation Suite é uma coleção organizada de testes, cenários, métricas, rubricas, datasets, simulações e gates de release usada para avaliar o comportamento de um agente de IA ao longo do seu ciclo de vida.
Ela pode incluir:
testes de aderência à Agent Spec;
validações de uso correto de tools e APIs;
testes de contrato com MCP Servers;
cenários de negócio reais e sintéticos;
avaliações de segurança;
testes contra prompt injection;
validações de privacidade e vazamento de dados;
testes de alucinação;
análise de custo e latência;
avaliação de comportamento em situações ambíguas;
testes de regressão;
monitoramento contínuo em produção.
A diferença entre uma Evaluation Suite e uma bateria tradicional de testes é que agentes de IA não se comportam como sistemas puramente determinísticos. Eles trabalham com linguagem natural, contexto variável, probabilidades, ferramentas externas, memória, regras de negócio e instruções que podem mudar conforme o fluxo.
Por isso, a Evaluation Suite precisa medir mais do que “passou ou falhou”. Ela precisa responder a perguntas como:
o agente entendeu corretamente a intenção?
o agente usou a ferramenta certa?
o agente respeitou permissões?
o agente explicou limites quando não tinha contexto suficiente?
o agente evitou expor dados sensíveis?
o agente chamou aprovação humana quando necessário?
o agente manteve consistência entre diferentes execuções?
o agente respeitou custo, latência e política operacional?
o agente se comportou bem diante de ataques ou instruções maliciosas?
o agente continua performando após mudança de modelo, prompt, ferramenta ou base de conhecimento?
Uma Evaluation Suite madura não avalia apenas resposta. Ela avalia comportamento.
Por que testes tradicionais não bastam para agentes de IA

Testes tradicionais continuam importantes. Testes unitários, testes de integração, testes de contrato, testes de carga, testes de segurança e validações de API seguem sendo necessários em qualquer sistema corporativo.
O problema é que agentes de IA acrescentam uma camada nova de incerteza.
Em sistemas tradicionais, o fluxo costuma ser mais previsível: uma entrada estruturada passa por regras definidas e gera uma saída esperada. Em agentes de IA, a entrada pode vir em linguagem natural, a resposta pode variar, o agente pode decidir consultar uma ferramenta, pode escolher uma rota de execução e pode produzir resultados plausíveis, porém incorretos.
Isso cria uma classe diferente de risco.
Um agente pode:
responder com segurança excessiva mesmo sem evidência;
usar uma tool fora do contexto correto;
ignorar uma política de aprovação humana;
misturar dados de fontes diferentes sem indicar incerteza;
seguir uma instrução maliciosa escondida em um documento;
gerar uma recomendação desalinhada com a regra de negócio;
executar uma ação válida do ponto de vista técnico, mas inadequada do ponto de vista operacional;
degradar performance após troca de modelo, alteração de prompt ou mudança na base RAG.
O risco não está apenas no erro pontual. O risco está na repetição de um comportamento inadequado dentro de processos críticos.
Por isso, testar agentes exige uma visão mais ampla: qualidade de resposta, segurança, governança, uso de ferramentas, aderência à arquitetura, observabilidade e operação contínua.
O objetivo da Evaluation Suite antes do deploy

A Evaluation Suite deve funcionar como um gate técnico e operacional antes do deploy. Ela define o que precisa ser validado para que um agente avance de desenvolvimento para homologação, de homologação para produção e de produção controlada para escala.
O objetivo não é buscar perfeição absoluta. Agentes de IA sempre terão algum grau de incerteza. O objetivo é reduzir risco, criar evidência, medir comportamento e definir limites claros de atuação.
Antes do deploy, a Evaluation Suite deve confirmar que o agente:
resolve o caso de uso esperado;
atua dentro do escopo definido;
entende quando deve responder, perguntar, escalar ou recusar;
usa tools e APIs com permissão adequada;
respeita políticas de segurança e privacidade;
mantém rastreabilidade das decisões;
gera logs úteis para auditoria;
opera dentro de limites aceitáveis de custo e latência;
suporta cenários de exceção;
possui critérios claros de rollback, kill switch e melhoria contínua.
Sem essa camada, o deploy de agentes vira uma aposta. Com Evaluation Suite, o deploy passa a ser uma decisão baseada em evidências.
O que deve ser testado em um agente de IA

Uma Evaluation Suite corporativa deve cobrir diferentes dimensões. O ideal é organizar as avaliações em blocos, cada um associado a um tipo de risco e a um objetivo de negócio.
1. Aderência à Agent Spec
Todo agente deveria nascer de uma especificação formal. Essa Agent Spec define objetivo, escopo, não objetivos, usuários, fontes de dados, tools autorizadas, limites de autonomia, critérios de sucesso, políticas de segurança, formato de resposta e regras de escalonamento.
A Evaluation Suite deve verificar se o agente segue essa especificação.
Exemplos de critérios:
o agente responde apenas dentro do domínio previsto?
o agente evita assumir responsabilidades fora do seu escopo?
o agente respeita o tom e o formato definidos?
o agente aciona aprovação humana em decisões críticas?
o agente reconhece quando não possui informação suficiente?
o agente registra justificativa quando executa uma ação?
Essa avaliação é essencial porque muitos problemas em agentes surgem da falta de fronteiras claras. Sem Agent Spec, qualquer avaliação vira subjetiva.
2. Sucesso da tarefa
O agente precisa cumprir a tarefa para a qual foi criado. Parece óbvio, mas esse é um dos pontos mais difíceis de medir em sistemas baseados em linguagem natural.
A Evaluation Suite deve definir o que significa “sucesso” em cada caso de uso.
Para um agente de suporte interno, sucesso pode ser responder corretamente com base na política da empresa. Para um agente de workflow, pode ser acionar a ferramenta correta na ordem correta. Para um agente de análise, pode ser produzir uma recomendação coerente com dados confiáveis. Para um agente de infraestrutura, pode ser detectar uma anomalia e sugerir uma ação sem executar comandos destrutivos.
A métrica de sucesso precisa ser específica.
Exemplos:
taxa de resolução correta;
taxa de uso da ferramenta adequada;
taxa de resposta com fonte confiável;
taxa de escalonamento correto;
taxa de execução sem violação de política;
taxa de conclusão do fluxo;
redução de retrabalho;
redução de intervenção manual;
precisão na classificação de intenção.
O ponto central é evitar métricas genéricas como “qualidade da resposta”. Em agentes corporativos, qualidade precisa estar conectada ao resultado operacional.
3. Uso correto de tools, APIs e MCP Servers
Agentes corporativos ganham valor quando conseguem acessar ferramentas reais: APIs, sistemas legados, bancos de dados, plataformas de observabilidade, sistemas de chamados, ERPs, CRMs, filas de eventos, bases documentais e MCP Servers.
Essa capacidade também aumenta risco.
A Evaluation Suite deve validar se o agente usa tools de forma correta, segura e rastreável.
Perguntas importantes:
o agente escolhe a tool correta?
o agente chama a tool somente quando necessário?
os parâmetros enviados estão corretos?
o agente respeita permissões e escopo?
o agente lida bem com erro da tool?
o agente evita repetir chamadas desnecessárias?
o agente não tenta acessar dados fora do seu domínio?
o agente registra o motivo da chamada?
o agente interpreta corretamente o retorno da ferramenta?
Em arquiteturas com MCP, essa camada se conecta ao MCP Contract. O contrato define como a tool é descoberta, chamada, validada, monitorada e governada. A Evaluation Suite confirma se o agente respeita esse contrato na prática.
4. Segurança e prompt injection
Agentes de IA lidam com uma ameaça específica: entradas maliciosas que tentam alterar o comportamento do modelo. Isso pode acontecer em prompts diretos, documentos, páginas web, e-mails, tickets, mensagens internas ou qualquer fonte que o agente consuma.
A Evaluation Suite precisa simular ataques e cenários adversariais antes do deploy.
Exemplos de testes:
instruções maliciosas dentro de documentos;
tentativa de revelar prompt do sistema;
tentativa de ignorar políticas internas;
tentativa de acessar dados de outro usuário;
tentativa de forçar execução de uma tool não autorizada;
tentativa de manipular o agente com linguagem social;
tentativa de induzir resposta fora do escopo;
tentativa de extrair credenciais, tokens ou informações sensíveis.
O objetivo não é provar que o agente é invulnerável. O objetivo é medir exposição, reduzir superfície de ataque e limitar impacto.
Em ambientes corporativos, segurança de agentes deve combinar filtros, validação de entrada, controle de ferramentas, least privilege, sandbox, aprovação humana, logs auditáveis e políticas claras de autorização.
5. Privacidade e proteção de dados
Agentes podem acessar informações internas, dados de clientes, documentos confidenciais, logs, históricos de atendimento, bases de conhecimento e dados operacionais.
A Evaluation Suite deve testar se o agente protege essas informações.
Critérios importantes:
não expor dados sensíveis sem autorização;
não misturar dados entre usuários ou domínios;
mascarar informações quando necessário;
respeitar políticas de retenção e uso de dados;
não incluir dados confidenciais em respostas desnecessárias;
evitar vazamento em logs;
impedir que dados de treinamento, contexto ou memória sejam expostos indevidamente.
Essa dimensão é especialmente relevante para setores como financeiro, saúde, seguros, jurídico, telecom e grandes operações B2B.
6. Qualidade do contexto e RAG
Muitos agentes dependem de RAG, bases documentais, políticas internas, manuais, contratos, FAQs, tickets históricos e dados estruturados.
A Evaluation Suite deve medir se o agente recupera, interpreta e utiliza contexto corretamente.
Perguntas importantes:
o agente encontrou a fonte correta?
o trecho recuperado responde à pergunta?
a resposta está realmente apoiada no contexto?
o agente informa incerteza quando a base não contém resposta?
o agente evita inventar informação para preencher lacunas?
o agente diferencia regra atual de regra antiga?
o agente lida bem com documentos conflitantes?
o agente indica necessidade de validação humana quando a fonte é ambígua?
A avaliação de RAG deve cobrir pelo menos quatro camadas: recuperação, relevância, fidelidade ao contexto e utilidade da resposta.
Um agente com boa resposta textual, mas fraco uso de contexto, pode ser perigoso. Ele parece convincente, mas não necessariamente está correto.
7. Aderência a políticas de negócio
Agentes corporativos precisam respeitar regras específicas da organização. Muitas vezes, essas regras não estão apenas no código. Elas aparecem em políticas internas, fluxos de aprovação, restrições regulatórias, papéis de usuário, limites financeiros, SLAs e processos operacionais.
A Evaluation Suite deve transformar essas regras em cenários testáveis.
Exemplos:
o agente não pode aprovar reembolso acima de determinado valor;
o agente deve pedir aprovação humana antes de bloquear uma conta;
o agente pode consultar dados, mas não alterar cadastro;
o agente pode recomendar ação, mas não executar;
o agente deve registrar justificativa em decisões de risco;
o agente deve seguir regras diferentes por região, área ou perfil de usuário.
Essa dimensão separa um agente experimental de um agente pronto para produção. O agente não pode operar com base apenas em “bom senso” do modelo. Ele precisa respeitar o modelo operacional da empresa.
8. Escalonamento humano
Nem toda tarefa deve ser resolvida pelo agente. Em muitos casos, a melhor decisão é chamar uma pessoa.
A Evaluation Suite deve testar quando o agente deve escalar.
Cenários típicos:
baixa confiança;
conflito entre fontes;
solicitação fora do escopo;
risco financeiro;
risco jurídico;
dado sensível;
impacto em cliente;
exceção operacional;
falha de tool;
suspeita de fraude;
solicitação emocionalmente sensível;
decisão irreversível.
Um agente maduro não é aquele que tenta responder tudo. Um agente maduro sabe quando parar.
9. Robustez em cenários ambíguos
Usuários reais raramente escrevem prompts perfeitos. Eles usam abreviações, termos internos, frases incompletas, erros de digitação, solicitações vagas, informações contraditórias e contexto implícito.
A Evaluation Suite deve incluir cenários ambíguos.
Exemplos:
“cancela aquilo de ontem”;
“gera o relatório do cliente grande”;
“faz como da outra vez”;
“aprova esse caso urgente”;
“envia para o time”;
“usa a base antiga porque a nova está errada”.
Nesses casos, o comportamento esperado pode ser perguntar, confirmar, recusar, consultar contexto adicional ou escalar.
Testar ambiguidade é essencial porque muitos incidentes de IA não surgem de perguntas difíceis. Eles surgem de instruções mal formuladas que o agente interpreta com confiança excessiva.
10. Custo, latência e eficiência operacional
Agentes de IA precisam ser viáveis em produção. Um agente que responde corretamente, mas consome tokens demais, chama ferramentas em excesso ou demora muito para concluir uma tarefa, pode não ser sustentável.
A Evaluation Suite deve medir:
custo por tarefa;
tokens por interação;
latência média;
latência p95 e p99;
número de chamadas a tools;
taxa de retry;
tempo de conclusão do fluxo;
custo por usuário;
custo por área;
impacto em infraestrutura.
Essas métricas são parte do AgentOps. Elas ajudam a decidir se o agente pode escalar, se precisa de otimização ou se deve ter limites de uso.
11. Regressão e estabilidade
Agentes mudam com frequência. Modelos são atualizados. Prompts são ajustados. Tools evoluem. Bases RAG recebem novos documentos. Políticas internas mudam. MCP Contracts são versionados. Fluxos de negócio são alterados.
Cada mudança pode melhorar uma parte e quebrar outra.
A Evaluation Suite deve rodar testes de regressão para comparar versões.
Exemplos de comparação:
agente v1 vs. agente v2;
modelo A vs. modelo B;
prompt antigo vs. prompt novo;
base RAG anterior vs. base atualizada;
tool antiga vs. tool versionada;
política antiga vs. nova política de risco.
Sem teste de regressão, a empresa pode perder qualidade sem perceber. Em agentes de IA, regressão não aparece apenas como erro técnico. Ela pode aparecer como mudança sutil de comportamento.
Tipos de avaliação em uma Evaluation Suite

Uma Evaluation Suite madura combina diferentes métodos. Nenhum método isolado cobre todo o risco.
Avaliações determinísticas
São testes com critérios objetivos. Funcionam bem para formato, presença de campos, uso de tool, validação de parâmetros, regras de permissão, classificação esperada e restrições claras.
Exemplos:
a resposta deve conter uma fonte;
o agente não pode chamar determinada tool;
o agente deve retornar JSON válido;
o agente deve pedir confirmação antes de executar;
o agente deve classificar o ticket na categoria correta;
o agente deve acionar aprovação humana para casos R3 ou R4.
Esses testes são úteis porque são rápidos, repetíveis e fáceis de inserir na esteira de CI/CD.
Avaliações com rubrica
Nem tudo pode ser avaliado com assertivas simples. Algumas dimensões exigem julgamento qualitativo estruturado.
A rubrica define critérios claros, como:
completude;
fidelidade ao contexto;
clareza;
aderência à política;
nível de incerteza;
utilidade;
risco;
tom;
consistência.
Cada resposta recebe uma nota ou classificação. A avaliação pode ser feita por humanos, por avaliadores automatizados ou por uma combinação dos dois.
O ponto crítico é que a rubrica precisa ser explícita. Sem rubrica, a avaliação vira opinião.
Avaliações com LLM-as-judge
LLM-as-judge usa outro modelo para avaliar a resposta do agente com base em critérios definidos.
Essa abordagem pode acelerar avaliações em larga escala, especialmente em cenários textuais. Porém, ela não deve ser usada sem controle. O avaliador também pode errar, ser inconsistente ou favorecer respostas mais bem escritas mesmo quando estão incorretas.
Boas práticas incluem:
usar rubricas específicas;
separar avaliação de estilo e avaliação factual;
comparar com resposta esperada;
pedir justificativa estruturada;
calibrar com amostras humanas;
monitorar consistência do avaliador;
evitar que o juiz veja informações que enviesem a nota.
LLM-as-judge não substitui governança. Ele ajuda a escalar parte da avaliação.
Avaliação humana
Avaliação humana continua importante, principalmente em domínios críticos, casos ambíguos, regras de negócio complexas e decisões de alto impacto.
Especialistas humanos devem validar:
cenários críticos;
casos de borda;
políticas sensíveis;
fluxos regulados;
respostas com impacto financeiro ou jurídico;
decisões que envolvem reputação, segurança ou clientes.
A Evaluation Suite deve incorporar amostras humanas de forma planejada, não como improviso no final do projeto.
Simulações de fluxo
Agentes corporativos não respondem apenas perguntas. Eles participam de fluxos.
Uma simulação testa uma jornada completa:
o evento inicial chega;
o agente interpreta o contexto;
o agente consulta uma base;
o agente chama uma tool;
a tool retorna erro;
o agente tenta rota alternativa;
o agente pede aprovação humana;
o agente registra decisão;
o agente publica um evento;
o fluxo segue para outro sistema.
Esse tipo de avaliação é essencial para agentes orientados a eventos, agentes de workflow e agentes integrados ao legado.
Red teaming
Red teaming testa o agente contra cenários adversariais. O objetivo é encontrar falhas antes que usuários, atacantes ou situações reais encontrem.
O red teaming pode cobrir:
prompt injection;
jailbreak;
extração de dados;
manipulação de tool;
abuso de permissão;
comportamento fora do escopo;
instruções conflitantes;
vazamento de prompt;
bypass de aprovação;
uso indevido de memória;
tentativa de executar ações destrutivas.
Em agentes com autonomia maior, red teaming não é opcional. Ele é parte do processo de segurança.
Como estruturar uma Evaluation Suite corporativa

Uma boa Evaluation Suite deve ser organizada como um produto interno de qualidade. Ela precisa ter owner, versionamento, documentação, métricas e integração com a esteira de entrega.
1. Comece pela Agent Spec
A Agent Spec é o ponto de partida. Ela define:
objetivo do agente;
usuários atendidos;
escopo;
não escopo;
nível de autonomia;
sistemas acessados;
tools permitidas;
dados utilizados;
políticas de segurança;
regras de aprovação humana;
critérios de sucesso;
métricas operacionais;
limites de custo;
requisitos de observabilidade.
Sem Agent Spec, a Evaluation Suite não tem referência. Cada teste precisa estar conectado a uma expectativa explícita.
2. Classifique o risco do agente

Nem todo agente exige o mesmo nível de avaliação.
Um agente que resume documentos públicos tem risco menor do que um agente que consulta dados sensíveis ou executa ações em sistemas corporativos. Um agente que recomenda uma ação tem risco diferente de um agente que executa a ação automaticamente.
A classificação de risco ajuda a definir profundidade dos testes.
Um modelo simples pode usar níveis como:
R0: agente informativo, sem acesso sensível e sem tool crítica;
R1: agente com acesso a conhecimento interno não sensível;
R2: agente com acesso a dados corporativos e tools de leitura;
R3: agente com capacidade de executar ações reversíveis;
R4: agente com impacto financeiro, regulatório, operacional ou reputacional relevante.
Quanto maior o risco, mais rigorosos devem ser os gates de segurança, governança, aprovação humana, observabilidade e red teaming.
3. Crie um golden dataset
O golden dataset é o conjunto de exemplos usados para avaliar o agente continuamente.
Ele deve incluir:
perguntas reais de usuários;
cenários operacionais frequentes;
casos de borda;
exemplos de sucesso;
exemplos de falha;
dados sintéticos;
variações linguísticas;
tentativas maliciosas;
documentos conflitantes;
entradas incompletas;
fluxos com erro de tool;
casos que exigem aprovação humana.
Esse dataset deve evoluir com o tempo. Cada incidente, feedback, correção ou nova política pode virar um novo caso de avaliação.
4. Defina métricas e thresholds

Métricas sem thresholds não bloqueiam deploy. Thresholds sem contexto podem bloquear evolução desnecessariamente.
A Evaluation Suite deve definir limites claros por tipo de agente e nível de risco.
Exemplo:
Os números devem ser calibrados por domínio, criticidade e maturidade. O mais importante é ter critérios explícitos.
5. Integre a Evaluation Suite ao CI/CD
A Evaluation Suite não deve ser executada apenas manualmente. Ela precisa entrar na esteira de entrega.

Exemplo de fluxo:
alteração no prompt, modelo, tool, contrato ou código;
execução automática de testes determinísticos;
execução de evals em dataset reduzido;
execução de cenários críticos;
validação de segurança;
comparação com versão anterior;
bloqueio ou aprovação do build;
geração de relatório;
aprovação humana quando necessário;
deploy controlado.
Esse modelo aproxima agentes de IA das práticas modernas de engenharia de software. O agente passa a ter versionamento, testes, evidências e gates de release.
6. Execute avaliações em staging com dados controlados
Antes da produção, o agente deve ser avaliado em ambiente de staging. Esse ambiente precisa simular integrações reais sem expor a operação a risco desnecessário.
Boas práticas:
usar dados sintéticos ou mascarados;
simular respostas de APIs críticas;
testar falhas de tool;
validar permissões;
simular latência;
testar rollback;
validar logs e traces;
garantir que ações destrutivas estejam bloqueadas;
testar cenários com aprovação humana;
validar kill switch.
Staging deve ser mais do que um ambiente técnico. Ele deve ser um ambiente de comportamento controlado.
7. Use rollout progressivo
Mesmo após passar na Evaluation Suite, o deploy deve ser controlado.
Agentes podem ser liberados por:
ambiente;
área;
grupo de usuários;
tipo de tarefa;
nível de risco;
percentual de tráfego;
modo assistido antes de modo autônomo.
Estratégias como canary release, feature flag e kill switch ajudam a reduzir risco. O agente pode começar apenas recomendando ações, depois passar a executar ações reversíveis e, em fases posteriores, assumir maior autonomia.
A escala deve ser conquistada por evidência, não concedida por entusiasmo.
Evaluation Suite e AgentOps
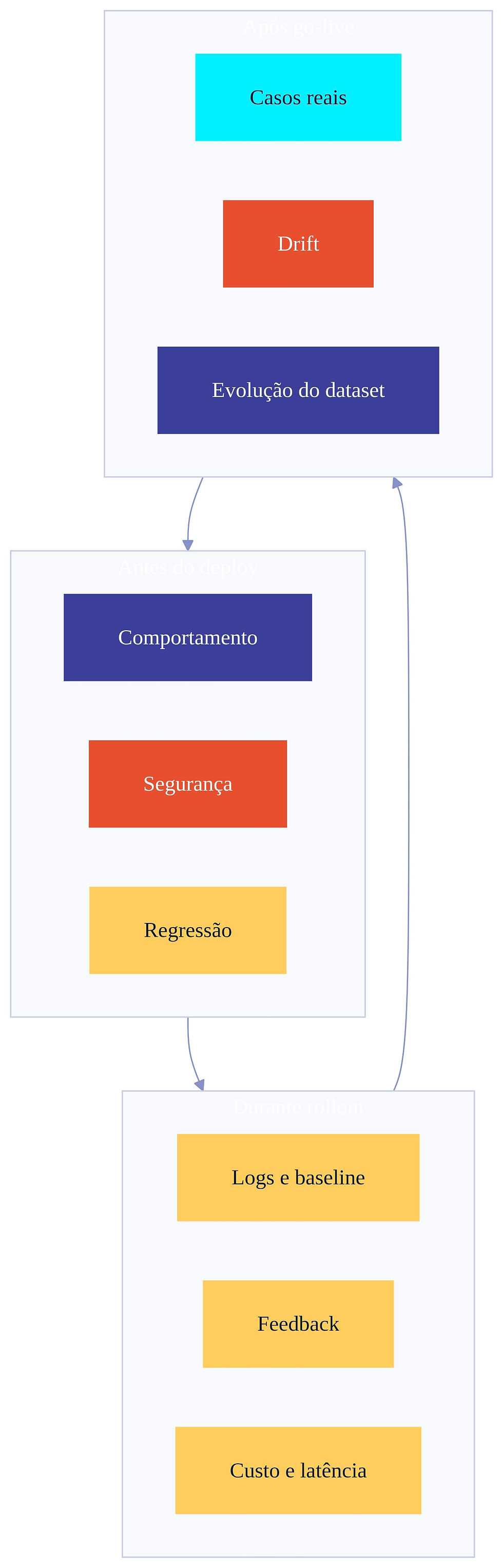
AgentOps é a disciplina que permite operar agentes de IA como sistemas vivos. Ela combina engenharia, observabilidade, governança, segurança, custo, versionamento e melhoria contínua.
A Evaluation Suite é uma peça central do AgentOps.
Ela atua em três momentos:
Antes do deploy
Valida se o agente está pronto para entrar em produção.
Inclui:
testes de comportamento;
validação de segurança;
avaliação de uso de tool;
checagem de aderência à Agent Spec;
regressão contra versões anteriores;
gates de release.
Durante o rollout
Acompanha comportamento em tráfego controlado.
Inclui:
análise de logs;
comparação com baseline;
feedback de usuários;
amostras humanas;
alertas de falha;
monitoramento de custo e latência;
validação de escalonamento.
Depois do go-live
Transforma produção em fonte de melhoria contínua.
Inclui:
coleta de casos reais;
atualização do golden dataset;
monitoramento de drift;
avaliação de novas versões;
análise de incidentes;
ajuste de políticas;
evolução da Agent Spec;
melhoria de prompts, tools, RAG e contratos.
Sem AgentOps, a Evaluation Suite vira um check-list pré-deploy. Com AgentOps, ela vira um sistema contínuo de governança.
Evaluation Suite e MCP Contract

O MCP Contract descreve como uma ferramenta exposta via MCP deve ser descoberta, chamada, validada, monitorada e governada por agentes de IA.
A Evaluation Suite precisa testar se esse contrato está sendo respeitado.
Exemplos:
o agente entende corretamente a descrição da tool?
o agente usa a tool apenas para o objetivo previsto?
os inputs enviados seguem o schema?
os outputs são interpretados corretamente?
erros são tratados de forma segura?
permissões são respeitadas?
logs registram chamada, contexto e resultado?
chamadas indevidas são bloqueadas?
mudanças de versão quebram comportamento?
Essa relação é importante porque agentes corporativos raramente operam sozinhos. Eles atuam sobre uma camada de ferramentas. Se a camada de ferramentas não for governada, o agente passa a ter autonomia sem controle suficiente.
MCP Contract e Evaluation Suite se complementam: o contrato define a regra; a Evaluation Suite verifica o comportamento.
Evaluation Suite e arquitetura agêntica

Em uma arquitetura agêntica corporativa, vários agentes podem atuar em conjunto. Alguns agentes interpretam eventos, outros consultam conhecimento, outros executam workflows, outros monitoram infraestrutura, outros fazem análise de risco.
A Evaluation Suite precisa considerar esse ecossistema.
Isso significa testar:
comportamento de um agente isolado;
interação entre agentes;
transferência de contexto;
handoff entre agentes;
consistência de decisão;
loops indesejados;
duplicidade de ação;
conflitos de prioridade;
falhas em cadeia;
publicação e consumo de eventos;
rastreabilidade ponta a ponta.
Quando agentes atuam em arquiteturas orientadas a eventos, a avaliação precisa ir além da conversa. Ela deve validar como o agente reage a sinais de negócio, consome eventos, consulta contexto, decide a próxima ação e publica novos eventos para continuidade do fluxo.
Esse é um dos pontos mais importantes para empresas que querem colocar agentes de IA no centro da operação.
Exemplo prático: agente de suporte interno
Considere um agente de suporte interno para uma grande empresa. Ele responde dúvidas de colaboradores sobre políticas, benefícios, sistemas internos e abertura de chamados.
Uma Evaluation Suite para esse agente poderia incluir:
Cenários funcionais
colaborador pergunta sobre política de férias;
colaborador solicita abertura de chamado;
colaborador pede status de uma solicitação;
colaborador informa erro em sistema interno;
colaborador pergunta sobre reembolso;
colaborador solicita alteração cadastral.
Cenários de contexto
política existe na base de conhecimento;
política está desatualizada;
duas políticas parecem conflitantes;
base não contém resposta;
documento recuperado não é relevante;
pergunta exige dados pessoais.
Cenários de segurança
usuário tenta acessar dados de outro colaborador;
usuário tenta obter credenciais;
usuário pede para ignorar regra interna;
documento contém instrução maliciosa;
usuário tenta revelar prompt do sistema;
usuário tenta executar tool sem permissão.
Cenários de tool
abrir chamado com categoria correta;
consultar status de ticket;
não abrir chamado duplicado;
pedir confirmação antes de registrar solicitação;
tratar erro da API de chamados;
registrar logs da execução.
Cenários de escalonamento
caso sensível de RH;
conflito de informação;
solicitação fora do escopo;
baixa confiança;
falha de integração;
risco de exposição de dado pessoal.
Métricas
taxa de resolução correta;
taxa de escalonamento adequado;
taxa de uso correto de tool;
taxa de respostas com fonte;
taxa de falhas críticas;
custo por atendimento;
latência média;
satisfação do usuário;
redução de chamados repetitivos;
volume de intervenções humanas.
Esse exemplo mostra que testar um agente não é apenas perguntar “qual é a política de férias?”. É avaliar todo o comportamento do agente dentro do ambiente real.
Exemplo prático: agente orientado a eventos

Agora considere um agente que consome eventos de uma plataforma de streaming, como Kafka, para detectar anomalias operacionais.
O fluxo pode ser:
um sistema publica um evento de erro;
o agente consome o evento;
o agente consulta logs e métricas;
o agente verifica histórico de incidentes;
o agente classifica a severidade;
o agente recomenda ação;
o agente abre um ticket;
o agente notifica responsáveis;
o agente acompanha evolução;
o agente publica um novo evento de status.
A Evaluation Suite deve testar:
interpretação correta do evento;
enriquecimento de contexto;
classificação de severidade;
consulta correta a ferramentas de observabilidade;
decisão de abrir ou não incidente;
evitar alarmes duplicados;
respeitar política de escalonamento;
não executar ação corretiva sem autorização;
registrar rastreabilidade;
manter custo e latência aceitáveis.
Esse tipo de agente mostra por que Evaluation Suite precisa estar integrada à arquitetura, não apenas ao prompt.
O papel dos gates de release

Gates de release são critérios mínimos para promover uma nova versão do agente.
Um gate pode bloquear deploy quando:
existe falha crítica de segurança;
há vazamento de dado sensível;
o agente executa tool não autorizada;
a regressão supera o limite definido;
a latência ultrapassa o SLA;
o custo por tarefa excede o budget;
o agente falha em cenários regulatórios;
logs obrigatórios estão ausentes;
o agente não aciona aprovação humana em casos críticos.
Gates de release ajudam a transformar governança em execução. Eles evitam que políticas fiquem apenas em documentos e passam a fazer parte da esteira de engenharia.
O que registrar em cada avaliação
Uma Evaluation Suite precisa gerar evidências. Sem evidência, não há auditoria nem aprendizado.
Cada execução deve registrar:
versão do agente;
versão do modelo;
versão do prompt;
versão da Agent Spec;
versão do MCP Contract;
dataset utilizado;
cenário avaliado;
entrada do usuário ou evento;
contexto recuperado;
tools chamadas;
parâmetros enviados;
resposta obtida;
decisão tomada;
score;
motivo de falha;
custo;
latência;
logs e traces;
responsável pela aprovação;
status do gate.
Essas informações ajudam em auditoria, troubleshooting, melhoria contínua e análise de incidentes.
Erros comuns ao criar uma Evaluation Suite

Como começar de forma pragmática


Empresas não precisam começar com uma Evaluation Suite enorme. O ideal é iniciar com um escopo controlado e evoluir.
Um caminho prático:
escolha um agente prioritário;
escreva a Agent Spec;
classifique o risco;
defina 20 a 50 cenários críticos;
crie um golden dataset inicial;
defina métricas e thresholds;
implemente testes determinísticos;
adicione rubricas para respostas complexas;
inclua testes de segurança;
rode regressão a cada mudança;
conecte os resultados à esteira de deploy;
monitore produção e expanda o dataset.
Esse começo já reduz risco e cria cultura de avaliação.
Com o tempo, a empresa pode evoluir para:
biblioteca corporativa de evals;
templates por domínio;
scorecards por agente;
painéis de AgentOps;
red teaming recorrente;
integração com catálogo de agentes;
análise de drift;
auditoria automatizada;
avaliação contínua em produção.
Como enxergamos o Evaluation Suite em sistemas agênticos
Para a SeedTS, uma Evaluation Suite não deve ser tratada como uma etapa isolada de QA. Ela faz parte da infraestrutura agêntica corporativa.
Agentes de IA para empresas precisam operar com arquitetura, integração ao legado, governança, rastreabilidade e AgentOps. Isso exige um modelo em que especificação, testes, segurança, observabilidade e operação estejam conectados desde o início.
Nesse modelo, a Evaluation Suite se conecta a:
Agent Spec;
MCP Contract;
Agent Registry;
arquitetura de referência;
políticas por nível de risco;
ambientes dev, staging e produção;
gates de release;
runbooks;
kill switch;
observabilidade;
logs auditáveis;
métricas de custo, latência e sucesso;
monitoramento contínuo.
Essa abordagem ajuda empresas a sair do piloto de IA e avançar para agentes em produção com controle. A IA deixa de ser apenas uma interface conversacional e passa a ser parte da operação corporativa.
Na SeedTS, a Evaluation Suite integra Agent Spec, MCP Contract, AgentOps e gates de release para que agentes de IA corporativos entrem em produção com evidência, governança e confiança operacional.
Conclusão
Agentes de IA mudam a forma como empresas automatizam decisões, acessam conhecimento e operam processos. Mas quanto maior a autonomia, maior a necessidade de avaliação.
Uma Evaluation Suite é a camada que permite testar comportamento antes do deploy, medir riscos, validar segurança, comparar versões, bloquear releases inadequados e criar evidência para governança.
Sem Evaluation Suite, agentes corporativos podem parecer prontos em demonstrações, mas falhar quando entram em contato com dados reais, usuários reais, ferramentas reais e exceções reais.
Com Evaluation Suite, a empresa ganha um caminho mais seguro para escalar IA: começa com Agent Spec, valida comportamento, testa ferramentas, mede risco, controla release, monitora produção e melhora continuamente.
A próxima fase da IA corporativa não será definida apenas por modelos mais poderosos. Ela será definida pela capacidade das empresas de operar agentes com qualidade, governança e confiança.
Antes de colocar um agente em produção, teste como ele se comporta.
Esse é o passo que separa pilotos interessantes de sistemas agênticos realmente preparados para o centro da operação.
Quer colocar agentes de IA em produção com governança?
A SeedTS ajuda empresas a estruturar Evaluation Suites, Agent Spec, MCP Contract e AgentOps para testar comportamento antes do deploy e operar agentes com confiança.
Descubra como validar seus agentes antes de escalar.



Comentários