

Engenharia de Harness: como criar agentes de IA mais confiáveis em ambientes corporativos
- 9 de jun.
- 12 min de leitura
Atualizado: 12 de jun.

O problema não é apenas criar agentes. É confiar neles.
A adoção de agentes de IA avançou rapidamente nos últimos anos. Muitas empresas já utilizam copilots, assistentes internos e automações baseadas em modelos de linguagem para apoiar desenvolvimento de software, atendimento, análise de documentos, geração de relatórios, suporte operacional e tomada de decisão.
Mas, quando o agente sai do ambiente experimental e passa a atuar em processos corporativos reais, surgem perguntas difíceis:
Como garantir que o agente recebeu o contexto correto?
Como limitar o que ele pode executar?
Como validar se a resposta ou ação está correta?
Como auditar o que foi feito?
Como evitar que uma automação gere impacto indevido em sistemas críticos?
Como manter qualidade quando o comportamento do modelo pode variar?
Essas perguntas mostram uma mudança importante: a discussão não deve ficar restrita ao modelo de IA. O ponto central passa a ser a engenharia ao redor do agente. É nesse contexto que surge a ideia de Engenharia de Harness.
O que é Engenharia de Harness no desenvolvimento de agentes de IA?
Em termos simples, um harness é a estrutura que envolve um agente de IA para permitir que ele trabalhe com mais contexto, controle, segurança e capacidade de correção. Ele não substitui o modelo. Ele complementa o modelo.
O modelo de linguagem é responsável por interpretar instruções, raciocinar sobre tarefas, gerar respostas e acionar ferramentas. O harness cria o ambiente necessário para que isso aconteça de forma mais confiável.
Na prática, o harness pode incluir:
instruções de sistema;
regras de negócio;
documentação técnica;
padrões de arquitetura;
memória controlada;
catálogo de ferramentas;
permissões;
conectores com sistemas internos;
ambientes de sandbox;
testes automatizados;
análise estática;
observabilidade;
auditoria;
aprovação humana;
métricas de qualidade, custo, latência e risco.
A lógica é simples: quanto maior a autonomia do agente, maior precisa ser a qualidade do ambiente que o orienta e valida.
Por que agentes precisam de harness?
Agentes de IA operam de maneira diferente de softwares tradicionais. Um sistema convencional executa regras previamente definidas. Um agente interpreta objetivos, seleciona caminhos, usa ferramentas e pode tomar decisões intermediárias para concluir uma tarefa. Essa flexibilidade é poderosa, mas também aumenta o risco.
Um agente pode interpretar mal um requisito.Pode usar uma informação incompleta. Pode acionar uma ferramenta incorreta. Pode produzir uma resposta plausível, mas tecnicamente errada.Pode ignorar uma restrição de compliance se ela não estiver explícita. Pode repetir um erro se não houver feedback adequado. Por isso, agentes corporativos não devem ser tratados como simples interfaces de chat. Eles precisam ser tratados como componentes de software dentro de uma arquitetura governada.
A Engenharia de Harness existe para reduzir incerteza e aumentar previsibilidade.
Abaixo a arquitetura de uma ambiente Harness com seus principais componentes.
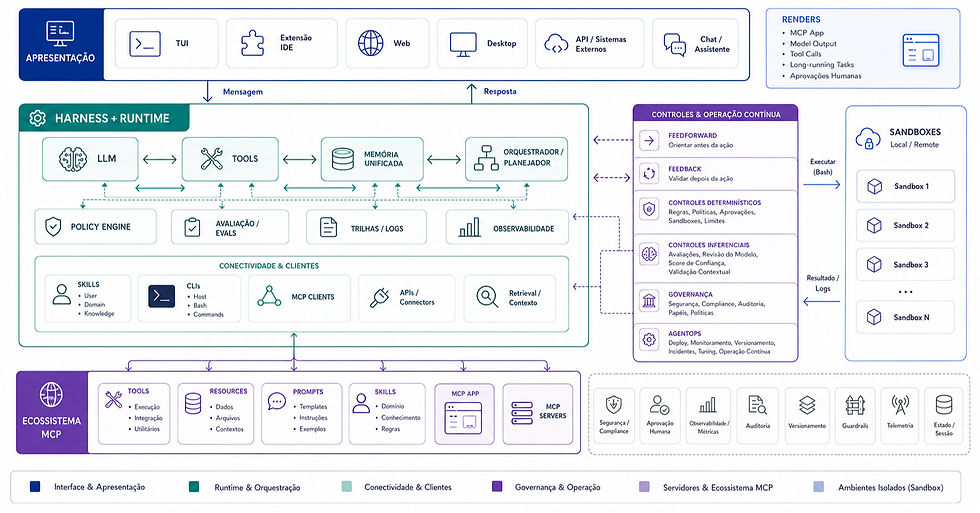
Arquitetura de uma ambiente Harness.
Feedforward: orientar antes da ação
Uma parte essencial do harness é orientar o agente antes que ele execute uma tarefa.
Esse tipo de orientação pode ser chamado de feedforward: um conjunto de informações, regras e restrições oferecidas previamente para aumentar a chance de o agente tomar boas decisões.
Exemplos de feedforward incluem:
especificações funcionais;
critérios de aceite;
documentação de APIs;
padrões de código;
regras de negócio;
políticas de segurança;
arquitetura de referência;
guias de integração;
instruções sobre ferramentas disponíveis;
exemplos de entradas e saídas esperadas;
limites de atuação do agente.
Sem feedforward, o agente precisa inferir demais. Isso aumenta ambiguidade e risco.
Com feedforward, a organização transforma conhecimento implícito em contexto explícito. O agente deixa de depender apenas da pergunta do usuário e passa a operar com base em uma estrutura mais rica.
Esse ponto é fundamental: antes de automatizar, é preciso organizar o conhecimento que orienta a automação.
Feedback: validar depois da ação
Uma segunda parte essencial do harness é o feedback.
Depois que o agente executa uma tarefa, o resultado precisa ser avaliado. Essa avaliação pode confirmar que a ação foi bem-sucedida, apontar erros ou acionar uma nova tentativa de correção.
Exemplos de feedback incluem:
testes automatizados;
linters;
type checkers;
análise estática;
validação de contratos;
scanners de segurança;
avaliação de aderência a requisitos;
revisão por outro agente;
revisão humana;
logs de execução;
métricas de sucesso;
alertas de falha;
comparação com resultados esperados.
Esse feedback fecha o ciclo de confiança. O agente não apenas executa. Ele executa, recebe sinais sobre a qualidade do resultado e pode ajustar o caminho.
Em ambientes corporativos, feedback é o que permite sair da lógica de “o agente respondeu” para a lógica de “o agente entregou algo validado”.
Controles determinísticos e controles inferenciais
Nem toda validação precisa ser feita por IA. Na verdade, muitos dos controles mais confiáveis continuam sendo determinísticos.
Controles determinísticos são aqueles que produzem resultados objetivos e repetíveis.
Por exemplo:
um teste passou ou falhou;
uma dependência tem vulnerabilidade conhecida;
um contrato de API foi quebrado;
uma regra de formatação foi violada;
uma métrica ultrapassou o limite;
uma permissão não está autorizada.
Esses controles são rápidos, baratos e confiáveis. Sempre que possível, devem ser priorizados.
Já os controles inferenciais são úteis quando a avaliação exige interpretação. Por exemplo:
a solução atende bem ao objetivo do usuário?
a resposta está coerente com o contexto?
a arquitetura proposta faz sentido?
a explicação está clara?
o agente respeitou o tom e o nível de detalhe esperado?
a decisão é defensável diante das informações disponíveis?
Nesse caso, outro modelo de IA, um agente avaliador ou um especialista humano pode ser usado para revisar o resultado.
A melhor abordagem combina os dois tipos: controles determinísticos para o que pode ser medido objetivamente e controles inferenciais para o que exige julgamento.
O papel do MCP na arquitetura agêntica
O Model Context Protocol (MCP) tem ganhado espaço porque resolve um problema recorrente: como conectar agentes de IA a ferramentas, dados e sistemas de forma padronizada.
Sem uma camada desse tipo, cada agente tende a criar integrações próprias. Isso gera duplicação, baixa governança, dificuldade de auditoria e risco operacional.
Com MCP, é possível organizar capacidades corporativas como serviços reutilizáveis por agentes. Um MCP Server pode expor, por exemplo:
consulta a bases de conhecimento;
acesso a documentos;
chamadas a APIs internas;
execução de comandos controlados;
consulta a logs;
ferramentas de desenvolvimento;
recursos de observabilidade;
fluxos de negócio;
prompts padronizados;
skills específicas de domínio.
Isso permite que agentes trabalhem com ferramentas reais, mas dentro de contratos claros. Para empresas com sistemas legados, esse ponto é especialmente relevante. A modernização não precisa começar pela substituição completa do legado. Muitas vezes, é possível criar uma camada de acesso governada, expondo capacidades existentes para agentes de IA com segurança e rastreabilidade.
Sandboxes: autonomia sem exposição desnecessária
Um agente que executa ações precisa de um ambiente seguro para testar, validar e errar sem comprometer sistemas críticos.
É por isso que sandboxes são componentes importantes em arquiteturas agênticas.
Um sandbox permite que o agente execute tarefas em um ambiente isolado. Ele pode rodar comandos, testar código, analisar arquivos, simular mudanças, validar hipóteses e produzir evidências antes que qualquer ação seja aplicada em ambientes sensíveis.
Isso é útil em vários cenários:
geração e revisão de código;
execução de testes;
análise de repositórios;
validação de scripts;
simulação de mudanças de infraestrutura;
análise de logs;
investigação de incidentes;
automação de tarefas operacionais;
geração de relatórios técnicos.
O sandbox reduz o risco de execução direta e cria um espaço intermediário entre recomendação e ação.
Essa separação é um princípio importante: agentes podem ter autonomia, mas essa autonomia deve ser proporcional ao risco da tarefa.
Memória: útil, mas precisa ser governada
Memória é outro elemento importante no harness. Ela permite que o agente mantenha contexto sobre preferências, histórico de interações, decisões anteriores, padrões do projeto e informações de domínio.
Mas memória não deve ser confundida com armazenamento livre e irrestrito.
Em ambientes corporativos, a memória precisa ser governada. É necessário definir:
o que pode ser armazenado;
por quanto tempo;
com qual finalidade;
quem pode acessar;
como remover informações sensíveis;
como separar memória de usuário, projeto e organização;
como auditar o uso;
como evitar que informações antigas gerem decisões incorretas.
Uma memória mal desenhada pode criar riscos de privacidade, segurança e qualidade. Uma memória bem projetada aumenta consistência e reduz retrabalho.
O objetivo não é fazer o agente “lembrar de tudo”. É fazer o agente acessar o contexto certo, no momento certo, com o nível adequado de permissão.
Governança: controle proporcional ao risco
Governança em IA não deve ser sinônimo de burocracia. O objetivo da governança é permitir escala com segurança.
Nem todo agente precisa do mesmo nível de controle. Um assistente que resume documentos públicos tem um perfil de risco. Um agente que executa ações em sistemas financeiros, jurídicos, operacionais ou regulados tem outro.
Por isso, uma boa prática é classificar agentes por nível de risco.
Essa classificação pode considerar:
sensibilidade dos dados acessados;
impacto das ações executadas;
grau de autonomia;
necessidade de aprovação humana;
exposição a clientes;
impacto financeiro;
impacto regulatório;
reversibilidade das ações;
criticidade do processo.
A partir dessa classificação, é possível definir políticas adequadas.
Agentes de baixo risco podem atuar com mais liberdade.Agentes de médio risco podem exigir logs, limites e revisão amostral.Agentes de alto risco podem exigir aprovação humana, dupla validação, ambiente controlado e trilhas de auditoria completas.
Essa abordagem evita tanto o excesso de bloqueio quanto a automação irresponsável.
AgentOps: operar agentes como software crítico
Quando agentes passam a fazer parte de processos reais, eles precisam ser operados como qualquer outro componente crítico de software.
Isso inclui práticas de AgentOps, que envolvem o ciclo de vida operacional dos agentes.
Algumas capacidades importantes de AgentOps são:
versionamento de agentes;
versionamento de prompts;
catálogo de ferramentas;
avaliação contínua;
monitoramento de qualidade;
controle de custo;
controle de latência;
logs auditáveis;
gestão de permissões;
análise de falhas;
detecção de comportamento inesperado;
métricas por tarefa;
rollback;
kill switch;
melhoria contínua.
Sem isso, a empresa pode até construir agentes úteis, mas terá dificuldade para mantê-los em produção com previsibilidade.
AgentOps é o que transforma agentes de IA em ativos operacionais gerenciáveis.
Engenharia de Harness no ciclo de desenvolvimento
A Engenharia de Harness também muda a forma como software é desenvolvido.
Em vez de usar IA apenas para gerar código, a organização pode aplicar agentes em várias etapas do ciclo:
descoberta de requisitos;
estruturação de escopo;
análise de impacto;
desenho de arquitetura;
geração de documentação;
revisão de código;
criação de testes;
validação de segurança;
preparação de deploy;
análise de logs;
suporte à operação.
Mas essa aplicação precisa de método. Cada etapa deve ter entradas, saídas, critérios de aceite e mecanismos de validação.
O erro comum é pedir que o agente “resolva” uma tarefa ampla demais sem contexto suficiente. O resultado tende a ser inconsistente.
Uma abordagem mais madura divide o trabalho em etapas menores, cada uma com agentes, ferramentas e validações específicas. Assim, o agente atua como parte de um processo de engenharia, não como substituto improvisado do processo.
Como avaliar se um agente está pronto para produção
Antes de colocar um agente em produção, algumas perguntas devem ser respondidas:
O agente tem objetivo claro?
Existe uma especificação do que ele deve e não deve fazer?
As ferramentas disponíveis estão documentadas?
As permissões seguem o princípio de menor privilégio?
Há logs de entrada, decisão, ferramenta acionada e saída?
Existem testes ou avaliações contínuas?
Há métricas de qualidade, custo e latência?
O agente sabe quando pedir ajuda humana?
Existe mecanismo de bloqueio ou desligamento?
A operação sabe como investigar falhas?
O comportamento foi testado com casos extremos?
O risco foi classificado?
Se essas respostas não estão claras, o agente provavelmente ainda está em estágio experimental.
A maturidade não está apenas na capacidade do agente de responder bem em uma demonstração. Está na capacidade de operar de forma consistente sob variação, erro, carga, exceções e restrições reais.
Um caminho prático para começar
Empresas que desejam adotar Engenharia de Harness não precisam começar com uma plataforma complexa. O caminho mais seguro é evolutivo.
Um roteiro prático pode seguir estas etapas:
Escolher um caso de uso relevante, mas com risco controlável.
Definir claramente o objetivo do agente.
Mapear dados, ferramentas e sistemas necessários.
Classificar riscos e limites de autonomia.
Criar instruções, regras e contexto mínimo.
Definir quais ações exigem aprovação humana.
Criar mecanismos de validação determinística.
Adicionar avaliações inferenciais quando necessário.
Executar em sandbox antes de produção.
Monitorar qualidade, custo, latência e falhas.
Registrar aprendizados e evoluir o harness.
Reutilizar padrões em novos agentes.
Essa abordagem evita dois extremos: projetos longos demais que nunca chegam à produção e automações rápidas demais que nascem sem controle.
Principais erros a evitar
A Engenharia de Harness ajuda a evitar alguns erros comuns em iniciativas de IA corporativa.
O primeiro erro é tratar prompt como arquitetura. Prompt é importante, mas não substitui integração, governança, validação e operação.
O segundo erro é dar ferramentas demais ao agente. Um agente com acesso amplo demais pode gerar riscos desnecessários. O ideal é aplicar escopo mínimo e permissões graduais.
O terceiro erro é não registrar decisões. Sem logs e trilhas de auditoria, fica difícil entender por que o agente agiu de determinada maneira.
O quarto erro é depender apenas de revisão humana. Humanos continuam essenciais, mas a escala exige sensores automatizados.
O quinto erro é medir apenas produtividade. Também é preciso medir qualidade, retrabalho, custo, latência, segurança e impacto operacional.
O sexto erro é colocar agentes em produção sem plano de rollback. Todo agente crítico precisa de mecanismos de contenção.
A arquitetura e sua execução simplificada em um ambiente Harness

A imagem representa uma arquitetura completa para execução de agentes de IA corporativos em um ambiente harness. Mais do que um simples agente conectado a um LLM, ela mostra todos os componentes necessários para transformar IA em uma plataforma operacional capaz de integrar sistemas, executar tarefas, acessar conhecimento corporativo e operar com segurança.
Cada bloco possui uma responsabilidade específica.
1. Camada de Apresentação
A camada superior representa os canais pelos quais usuários e sistemas interagem com o agente. Ela pode assumir diferentes formatos:
Interface Web
Aplicações Desktop
Extensões de IDE
Interfaces de linha de comando (CLI/TUI)
Aplicações especializadas construídas sobre MCP
O papel dessa camada é apenas capturar solicitações e exibir respostas. Ela não contém a inteligência principal do sistema. Quando um usuário envia uma mensagem, a solicitação é encaminhada para a camada de Runtime.
2. Harness + Runtime
Essa é a camada central da arquitetura. É nela que ocorre a orquestração da execução dos agentes. O Runtime funciona como um sistema operacional para agentes de IA, coordenando:
LLMs
Ferramentas
Memória
Skills
Integrações externas
Fluxos de execução
Sem essa camada, o agente seria apenas uma chamada isolada para um modelo de linguagem. O Runtime transforma o LLM em um sistema capaz de executar trabalho.
LLM
O LLM é o mecanismo responsável pelo raciocínio. Ele interpreta solicitações, planeja ações, toma decisões e gera respostas. Entretanto, sozinho ele não possui acesso aos sistemas corporativos. Para agir sobre o ambiente, ele precisa utilizar ferramentas.
Tools
As Tools representam as capacidades operacionais disponíveis para o agente.
Exemplos:
Consultar APIs
Executar scripts
Ler bancos de dados
Criar chamados
Consultar ERPs
Atualizar CRMs
Publicar eventos
As ferramentas são o que permitem que o agente saia do mundo das respostas textuais e execute ações reais.
Memória Unificada
A memória fornece contexto persistente para os agentes.
Ela pode armazenar:
Histórico de conversas
Contexto operacional
Preferências
Conhecimento corporativo
Estado de execução
Sem memória, cada interação seria tratada como um evento isolado.
Com memória, o agente consegue manter continuidade e contexto.
2.1. Conectividade
A camada de conectividade fornece acesso ao ecossistema operacional.
Ela expõe diferentes mecanismos de integração.
Skills
Skills representam capacidades especializadas. Uma skill pode encapsular:
Conhecimento de domínio
Procedimentos corporativos
Fluxos de negócio
Regras operacionais
Na prática, funcionam como módulos reutilizáveis que ampliam as capacidades dos agentes.
CLIs
Permitem que agentes executem comandos diretamente em ambientes controlados.
Exemplos:
Bash
Scripts Python
Ferramentas DevOps
Automações operacionais
Isso possibilita que agentes realizem tarefas administrativas, manutenção ou automação de infraestrutura.
MCP Clients
Os MCP Clients conectam o Runtime ao ecossistema MCP.
Por meio deles, os agentes descobrem e utilizam recursos disponibilizados por servidores MCP.
Isso cria um mecanismo padronizado para acesso a ferramentas, dados e serviços distribuídos.
3. Sandbox
A execução de ações ocorre dentro de ambientes isolados.
Cada Sandbox funciona como um ambiente controlado onde comandos podem ser executados sem impactar diretamente outros sistemas.
Essa separação oferece:
Segurança
Isolamento
Auditoria
Controle de permissões
Os agentes enviam tarefas para o Sandbox e recebem de volta:
Resultados
Logs
Evidências de execução
Esse modelo reduz riscos e aumenta a governança operacional.
4. Ecossistema MCP
A camada inferior representa os recursos disponibilizados para os agentes. Ela funciona como um catálogo corporativo de capacidades reutilizáveis.
Tools
Executam ações.
Exemplos:
Integrações
Serviços
Automações
Operações corporativas
Resources
Disponibilizam contexto e informação.
Exemplos:
Arquivos
Bancos de dados
Documentação
Bases de conhecimento
Prompts
Padronizam instruções e comportamentos.
Podem conter:
Templates
Políticas
Exemplos
Guias de execução
Skills
Representam conhecimento especializado encapsulado.
Podem implementar regras específicas de negócio ou capacidades técnicas avançadas.
MCP Apps
São aplicações completas construídas sobre o ecossistema MCP.
Elas podem combinar:
Ferramentas
Recursos
Skills
Interfaces próprias
para entregar experiências completas aos usuários.
Como o Fluxo Funciona na Prática
O fluxo completo pode ser resumido em seis etapas:
O usuário envia uma solicitação por uma interface.
O Runtime recebe a requisição.
O LLM interpreta o objetivo.
O agente identifica quais ferramentas e recursos precisam ser utilizados.
A execução ocorre através de MCP Clients e Sandboxes.
Os resultados retornam ao Runtime e são apresentados ao usuário.
Essa separação em camadas permite criar sistemas agênticos corporativos escaláveis, governáveis e seguros, nos quais agentes não apenas respondem perguntas, mas executam processos reais conectados ao ambiente operacional da empresa.
Conclusão: agentes confiáveis são resultado de engenharia
Agentes de IA representam uma mudança importante na forma como empresas podem automatizar conhecimento, decisões e operações. Mas o valor real não está apenas em conectar um modelo a uma interface.
O valor está em construir uma arquitetura que permita ao agente trabalhar com contexto, ferramentas adequadas, limites claros, validação contínua e governança proporcional ao risco.
Essa é a função da Engenharia de Harness. Ela transforma agentes em sistemas mais previsíveis.Transforma respostas em entregas verificáveis.Transforma ferramentas em capacidades governadas.Transforma autonomia em operação controlada.Transforma experimentos em software corporativo.
À medida que empresas avançam no uso de IA, a pergunta deixa de ser apenas
“Qual modelo vamos usar?”
e passa a ser:
Qual estrutura precisamos construir para que nossos agentes atuem com segurança, qualidade e confiança?
Essa pergunta é o ponto de partida para uma adoção de IA mais madura, pragmática e sustentável.


Comentários